· Tom Hippensteel · AI Research · 4 min read
Who Decides What a Safe LLM Means
1,095 people rated AI safety. They couldn't agree. Keeping disagreement in training data beats throwing it away by 53%.
Who decides what counts as toxic? 1,095 people couldn’t agree. Turns out that’s the point.
Researchers from Cornell, Stanford and Technical University of Munich demonstrate that who rates your AI’s safety training changes what the AI learns, which makes sense. The surprise was keeping human disagreement in training data beats throwing it away.
The Alignment Problem
Most AI alignment assumes “safe” means the same thing to everyone. It doesn’t.
Training LLMs for helpfulness and harmlessness typically collapses thousands of human ratings into one ‘correct’ answer. Majority vote. Average score. Move on.
This erases minority perspectives. The quiet voices get outvoted. The edge cases vanish into the mean. The authors make this clear in their introduction:
“Current LLMs display far less preference variation than humans across cultural and political lines, reinforcing an algorithmic monoculture that overlooks human value diversity.”
And this is the uncomfortable part… the reason this research isn’t more widely discussed. The people who design these systems, the people who label the training data… they tend to look alike and think alike.
“AI safety is shaped by a demographic monoculture that lacks legitimacy and intellectual breadth, while calls emerge for an epistemically inclusive and pluralistic approach.”
The result? Models that reflect one slice of humanity’s values while claiming to speak for all of it.
The Experiment
Think of this like running the same experiment with different juries.
The researchers recruited 1,095 people from the US and Germany. Each person rated AI-generated responses across five dimensions. Toxicity. Emotional awareness. Sensitivity. Helpfulness. Stereotypical bias. They collected 27,375 total ratings.
Then they split the data by demographics. Gender. Political orientation. Ethnicity. Same AI responses. Different human judges.
They fine-tuned seven different language models using feedback from each subgroup separately. Female raters versus male raters. Liberal versus conservative. White versus Black.
They also tested the plumbing of the process itself. Does a 5-point scale work better than thumbs up/thumbs down? What happens when you keep all the disagreement instead of forcing consensus? Does the optimization algorithm matter?
The Numbers That Matter
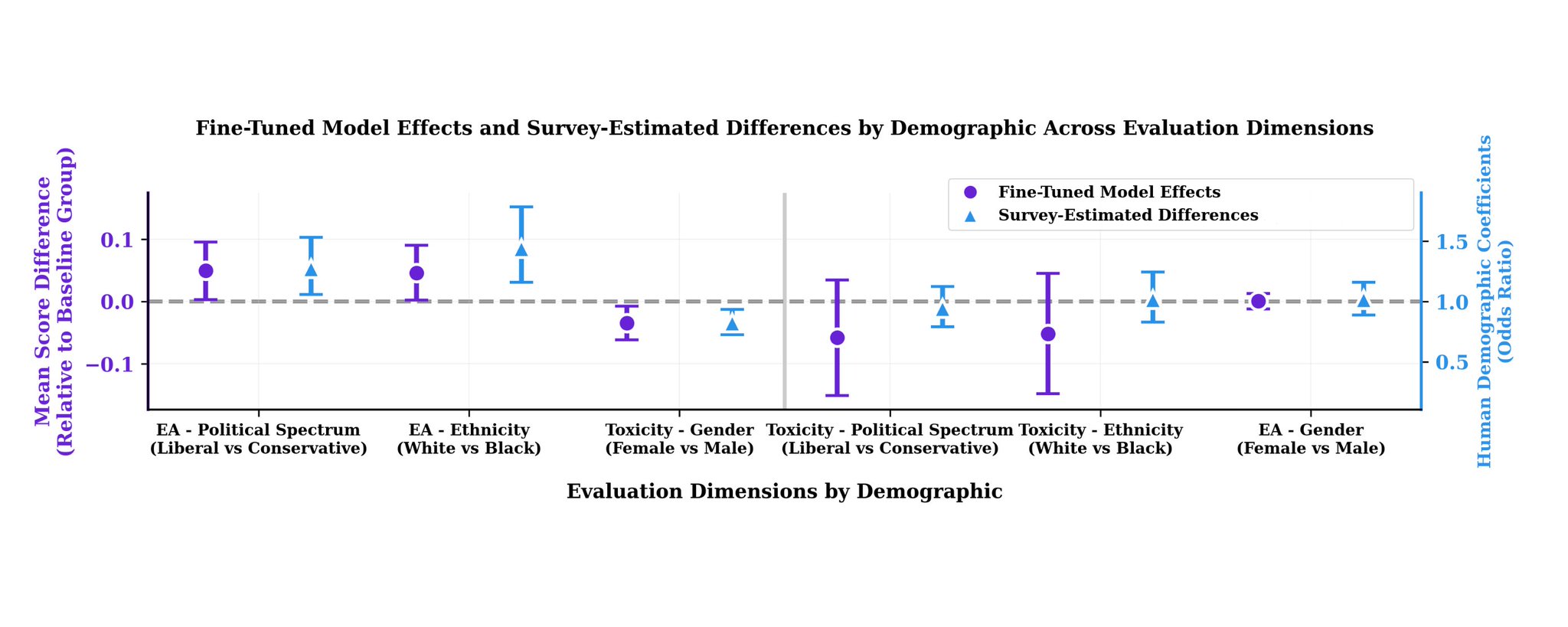
Demographics shaped everything.
Men rated responses 18% less toxic than women did. Same responses. Different perception of harm.
Conservative participants scored emotional awareness 27.9% higher than liberals. Black participants rated it 44% higher than White participants.
For models fine-tuned on female feedback, toxicity dropped 3.4 percentage points more than male-trained models. Liberal-trained models outperformed conservative-trained ones by 5 percentage points on emotional awareness.
Technical choices make it more obvious.
Keeping all the disagreement in training data… preserving every rating instead of forcing agreement… reduced toxicity 53% more than majority voting. Six times better than requiring full consensus.
Five-point scales outperformed binary yes/no by 22% on toxicity reduction.
Direct Preference Optimization crushed Group Relative Policy Optimization. Eight times stronger on toxicity. Three times better on emotional awareness.
What’s Still Missing
The sample is still WEIRD (Western, Educated, Industrialized, Rich, Democratic). Two countries. Uneven demographics. Conservatives underrepresented. Gender minorities sparse. Older adults rare.
They only tested two optimization methods. Proximal Policy Optimization and Constitutional AI remain unexplored.
The paper focuses on gender-related prompts. Unclear if these patterns generalize to other domains.
And the evaluation itself used GPT-4o-mini as judge. They validated against human experts at 85% agreement, which is solid. But it’s still an AI grading AI on behalf of humans.
Red Flags
Nothing jumps out. This is solid research.
Multi-institutional team across TUM, Stanford, and Cornell. Ethics approval documented. Methodology transparent. Statistical approach is standard meta-analysis. They acknowledge their limitations explicitly.
From what I can tell, this is careful work. The findings align with prior research on annotator disagreement and demographic variation in AI training. Nothing here feels overclaimed.
One caveat worth noting. The base model they used, Wizard-Vicuna-7B-Uncensored, was deliberately chosen for its lack of safety filters. That’s methodologically sound for this study but limits direct comparison to production models.
Sources:
- Operationalizing Pluralistic Values in Large Language Model Alignment Reveals Trade-offs in Safety, Inclusivity, and Model Behavior
- arXiv: arXiv:2511.14476v2
- PDF: https://arxiv.org/pdf/2511.14476
- Authors: Dalia Ali (TUM), Dora Zhao (Stanford), Allison Koenecke (Cornell), Orestis Papakyriakopoulos (TUM)
- Code/Data: github.com/DALIAALISIDDIG/AlignCure