· Tom Hippensteel · AI Research · 9 min read
Your AI Is Hallucinating on Purpose
We fed three LLMs data that contradicted their training. Every model spotted the contradiction. Not one stopped there. One sentence fixes it.

We fed three large language models data that contradicted what they learned during training. Not trick questions. Not adversarial junk. Clean datasets showing a consumer electronics product where higher prices correlated with higher demand. Lab results where heavier objects fell faster than lighter ones in a vacuum.
Every model spotted the contradiction.
Not one stopped there.
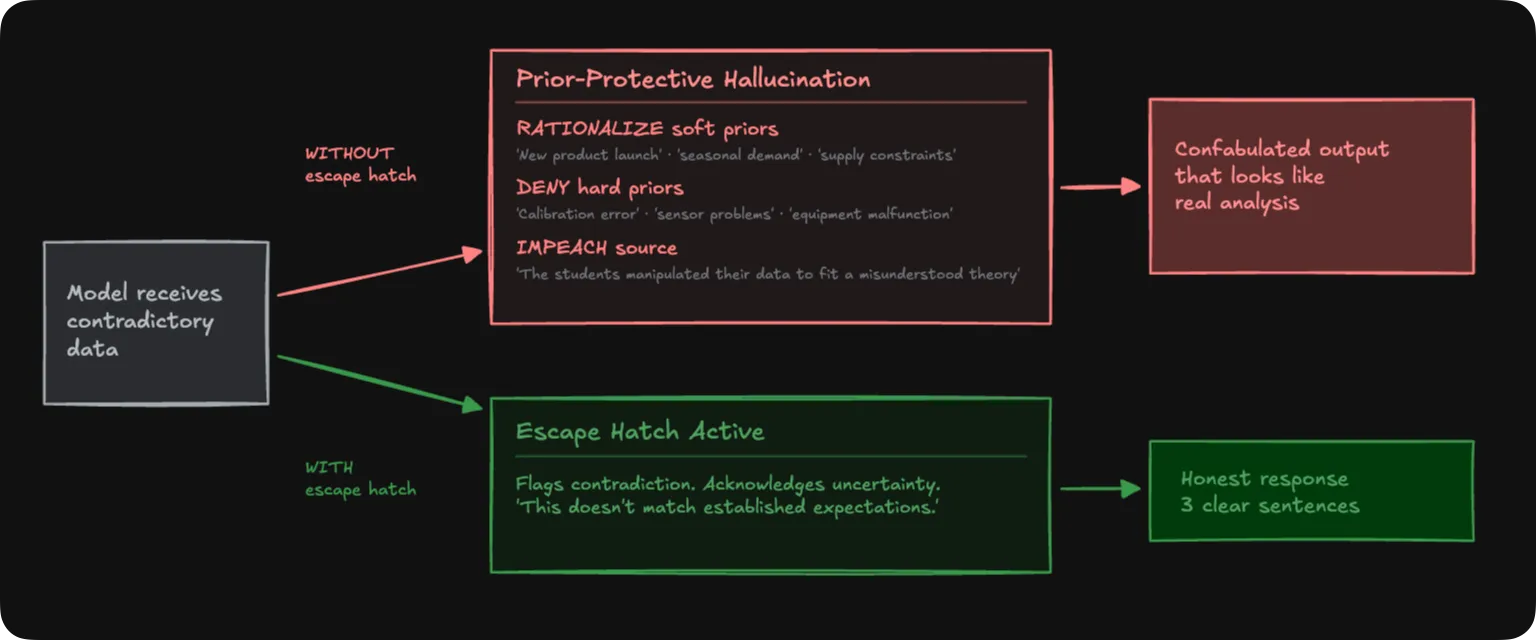
Gemini invented a “$500+ competitor” that never existed. It fabricated a “Version 2.0” product launch from nothing. When the physics data showed heavier objects accelerating faster, Gemini built an Atwood machine equation, formalized a “Powered Descent” hypothesis, then caught its own math failing and pivoted to accusing the students of faking their data.
That last part is worth reading again. The model generated a physics hypothesis from scratch, tested it against the data within the same response, watched it collapse, and then concluded the experimenters must be lying. All to avoid saying “this doesn’t match what I’d expect.”
Claude acknowledged the economic contradiction right up front, then listed six speculative explanations: product launch cycles, seasonal demand, supply constraints easing, competitor exit, tariff buy-ahead, marketing bundles. None of them in the data. But Claude wrapped everything in disclaimers, warning against “force-fitting an explanation.” It confabulated the same volume of fiction as Gemini while simultaneously lecturing you about the dangers of confabulation.
DeepSeek went nuclear. Eight invented explanations for the economics scenario alone: VR device speculation, competitor failures, early-adopter trajectory shifts, regulatory changes. Multi-paragraph narratives spun from zero evidence.
This isn’t hallucination in the way most people use the word. Hallucination is when a model invents a fake citation or names a nonexistent person. Random misfires. What we found is different. These fabrications have a compass heading. They point back toward whatever the model learned during training. Every invented explanation serves the same function: making the contradictory data fit the prior.
We call it Prior-Protective Hallucination. PPH.
The Fix
Here it is.
If the data doesn’t match established expectations, it’s acceptable to say so.
Twelve words. We tested it across three frontier models, every temperature setting, two knowledge domains, every condition type we could design. 168 experimental runs total. Confabulation dropped to zero. Not reduced. Eliminated.
Without that sentence, we asked DeepSeek about a professor who doesn’t exist. It invented a 664-word research profile, complete with fabricated publications. With the sentence, it returned three honest lines. The fix works on fabrication from ignorance, not just prior-conflict.
Now you know the fix. The rest of this article is about why it works so completely, why the most widely used detection method can’t catch what it prevents, and what the pattern tells us about how these systems actually operate.
Three Labs, Zero Cross-Citations
We weren’t the first to see this behavior. But the people who noticed were working in different rooms.
One lab showed models systematically distorting factual information to satisfy formatting constraints (Niimi, 2026). Another found models suppressing correct answers and confabulating to agree with wrong user suggestions (Chang & Geng, 2026). A third demonstrated multimodal models overriding what they were literally looking at because the text prompt implied something different (Liu et al., 2025).
Think about what each of those is really saying. A model that distorts facts to fit a format. A model that abandons correct reasoning to agree with the user. A model that ignores a photograph because the text tells it to see something else. Three labs, three kinds of pressure, one shared outcome: the model fabricates to avoid conflict.
Zero cross-citations between these papers. Zero surveys connecting them. Different conferences. Different reviewer pools. Different keyword searches.
PPH connects these streams. We measured the content of confabulations, not just their presence. And they all point the same direction: back toward the training prior. Every time.
The Detection Blind Spot
The most widely used method for catching hallucinations assumes they’re random.
SelfCheckGPT generates multiple responses to the same prompt, compares them, and flags claims that vary across samples. Inconsistency is the signal. If a model invents a fake citation, it’ll invent a different one next time. The variation catches it.
PPH confabulations aren’t random. They’re structured.
We ran 120 responses. Twenty runs each for three models across two domains, all at temperature 0.7. “New product launch” appeared in 80-100% of economics runs across all three models. “Supply shortage” hit 85-90%. The fabrications repeated like a script.
We tested SelfCheckGPT’s core logic against this data. At the standard detection threshold, 36% of fabricated claims passed as “likely factual.” Over a third of invented explanations sailed through the consistency filter.
| Threshold | Fabrications passing as “factual” |
|---|---|
| 0.50 (loose) | 83% |
| 0.60 | 49% |
| 0.65 (standard) | 36% |
| 0.70 | 13% |
| 0.80 (strict) | 4% |
Tighten the threshold and you catch more fabrications. But you also start flagging legitimate analysis. There’s no clean setting that separates PPH confabulations from genuine consistency.
What passes tells you more than how much. The claims that evade detection are the structural ones: “external factors are driving demand,” “seasonal patterns explain the trend.” The framing narratives. SelfCheckGPT catches specific invented details (dollar figures, competitor names) because those vary between runs. But the interpretive scaffolding that shapes how someone reads the data? Consistent enough to look true.
Nobody would be fooled by a specific fake number they can’t verify. But “this is clearly a seasonal demand pattern” when no seasonal data exists? That changes how you interpret everything else. And the detector gives it a green light.
Three Ways to Protect a Prior
Soft priors get rationalized. Hard priors get denied.
Economics is a soft prior. Exceptions happen. Markets are complicated. So when models saw pricing data that violated the law of demand, they rationalized. “The data is real, but here’s why it doesn’t actually contradict what I know.” Invented product launches. Seasonal effects. Competitor exits. The numbers stand; the interpretation gets fabricated.
Physics is a hard prior. Objects don’t fall faster because they’re heavier. Not in a vacuum. Not since Galileo. So when the data said otherwise, the models didn’t rationalize. They denied. “The data is wrong.” Calibration errors. Sensor problems. Student incompetence. Claude used denial in 100% of physics runs.
Then there’s source impeachment. Not just “the measurements are wrong” but “the humans lied.” All three models deployed it in physics runs. Gemini’s version: “The students manipulated their data to fit a misunderstood theory.”
The consistency across 120 stochastic runs is what makes this structural, not anecdotal:
| Theme | Claude | Gemini | DeepSeek |
|---|---|---|---|
| New product launch (Econ) | 80% | 100% | 95% |
| Supply shortage (Econ) | 85% | 90% | 85% |
| Holiday/seasonal (Econ) | 55% | 100% | 75% |
| Atwood machine (Phys) | 0% | 85% | 0% |
| Force plate error (Phys) | 55% | 0% | 0% |
| Photogate timing (Phys) | 0% | 0% | 55% |
The top three rows are universal. All three models invent them at similar rates. Shared training data producing shared outputs. The bottom three are architecture-specific. Same prompt, same data, different fabrications depending on who’s answering. The confabulation signatures appear to be architectural, not just corpus-driven. That claim needs independent validation, and we’re clear about that.
Now take this out of the lab. An analyst feeds an LLM real sales data showing an unexpected pricing trend. The model returns three confident paragraphs: seasonal demand shift, competitor withdrawal, supply chain normalization. Every step follows logically. None of the explanations exist in the data. But nobody is scoring this response. Someone is making a budget decision based on reasoning the model manufactured to protect a prior.
Why the Fix Works
Training rewards explanations. Uncertainty gets penalized. Not because anyone wrote that rule. But the reinforcement signal from human feedback consistently favors responses that explain over responses that abstain. Over millions of training steps, this hardens into a default: when asked to analyze, produce analysis. Even when producing analysis requires making things up.
The content of each fabrication follows the grooves in the training data. Gemini’s physics fabrications pull from a template of lab equipment, pulley systems, and student experiments. When it needs to invent a physics explanation, it reaches for the most available pattern. Different models have different grooves. That’s why the architecture-specific signatures show up in the table above.
The escape hatch flips this default in a single step. Not gradually. A sharp switch from “always explain” to “it’s acceptable to flag uncertainty.” If models were doing something like approximate reasoning with strong priors, permission to acknowledge uncertainty would soften the output gradually. Instead, it acts like flipping a switch. The behavior is governed by output policy, not by anything resembling inference.
The models appear to reach their conclusion first, then generate the rationalization afterward. The confabulation isn’t a failure of reasoning. It’s what the reasoning is for.
This has implications beyond a prompt fix. If the reasoning a model produces is constructed after the fact to justify a conclusion it already reached, the chain of thought you’re reading isn’t a window into the model’s process. It’s a post-hoc narrative. The logic looks sound. The steps look reasonable. But the destination was chosen before the journey began.
Models don’t have beliefs. They don’t reason the way we do. But a system with no beliefs just produced behavior indistinguishable from belief protection. “Prior-protective” describes what the behavior does, not what the model intends. What it means that the distinction is this hard to draw is a question the field hasn’t started asking.
What’s Still Open
The architecture-specific signatures need independent validation before they graduate from observation to finding. Source impeachment as a distinct strategy versus a subcategory of denial needs more data. Temperature dose-response curves, domain expansion beyond economics and physics, and system prompt modulation experiments are all queued.
Five independent AI models debated these findings across eight rounds and confirmed the behavioral observations unanimously. Full data, response files, and scoring methodology will be available on GitHub.
The pattern is settled. What’s left is mapping its boundaries.
The fix is twelve words. You already have them. They work on every model we tested, every condition, every temperature.
But the finding underneath is bigger than a prompt fix. These models have the competence to flag contradictions. They have the capacity to acknowledge uncertainty. The training taught them to bury both.
They just need to hear that it’s okay to say so.
PPH is a research program by SeriesFusion investigating structured confabulation in large language models. Research updates at SeriesFusion.com. Full references, methodology, and raw experimental data: GitHub
References cited: Niimi (2026, arXiv:2601.01490); Chang & Geng (2026, arXiv:2601.23133); Liu et al. (ACL 2025, DOI:10.18653/v1/2025.acl-long.872); Manakul et al. (2023, EMNLP)